I joined the BBC as a software engineer in Future Media for Audio & Music Interactive just over 5 years ago.
It was just before the first release of BBC Programmes, and it was a couple of months before the iPlayer streaming service on the web launched in December 2007.
I came to the BBC because having developed a number of research prototypes in academia for a few years, I wanted to build stuff with a significant number of real users. And I’ve certainly been able to do that, having worked:
It’s been incredible. I’ve learnt so much, not just from the technical side but also as an individual. I’ve worked with really brilliant developers, designers and editorial - making great friends along the way. I’ve worked on some amazing projects, and written code that is used by millions of users each week.
However, all good things must come to an end and I’ve decided it’s time for me to move on.
Friday was the last day at the BBC for me, and today I’m starting as a technical lead at Sidekick Studios.
Last weekend I participated in another Music Hack Day.
I managed to convince Kirsten Fletcher, to join me. Kirsten is a freelance costume designer-maker, who is more used to working on theatre and movie productions than hack days.
## Screecha
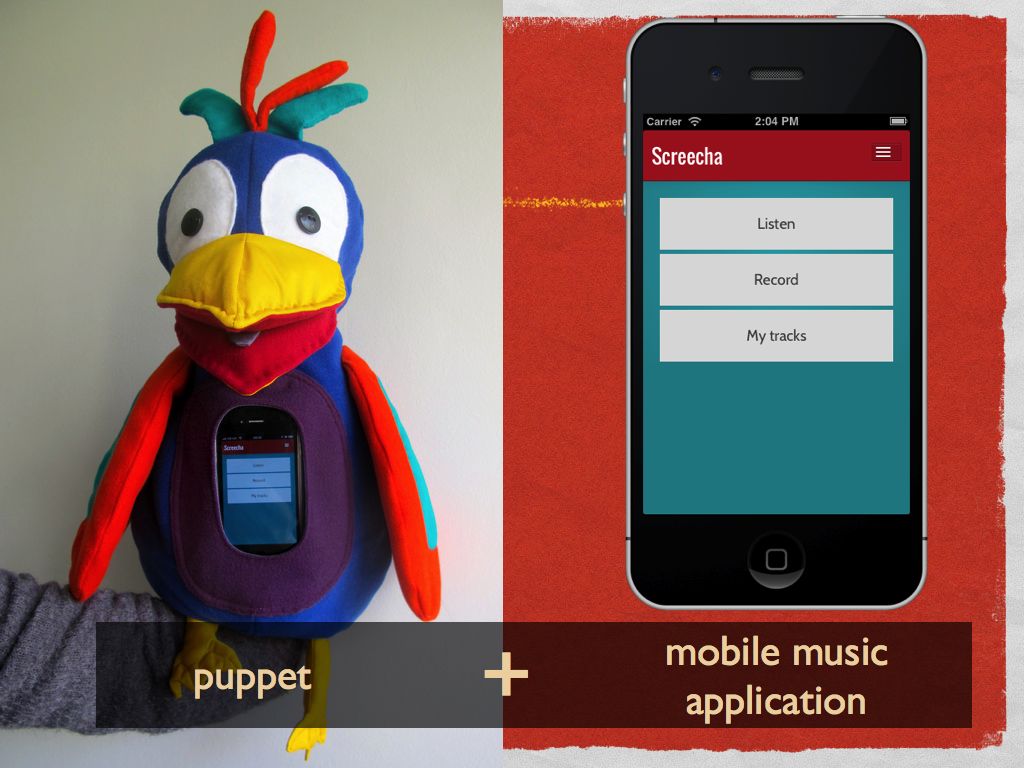
Together we made Screecha: an interactive musical toy aimed at children. It’s a puppet that can house a smart phone in it’s belly and an app to go with it.
Using the app, children can:
- listen to their favourite songs (using the Spotify Metadata API and Cocoalibspotify)
- view the lyrics as the song plays (using Echonest and Musixmatch)
- record their own songs and upload them to SoundCloud
- listen to the masterpieces they’ve previously uploaded to SoundCloud
As a song plays, the puppet can be manipulated to sing along with the music.
## The idea
The idea was mostly inspired by hanging out with some close friends who have a baby. They were talking about how many children’s songs and nursery rhymes were available on Spotify, which led us to think about a Spotify app as a physical toy.
We then started looking on other music services for children’s songs and came across a recording of a toddler singing “Twinkle, Twinkle Little Star” on SoundCloud. That’s when we decided that the ability of recording and saving children’s performances would add an interesting angle to the hack.
## Hacking with a sewing machine

While I was was doing the usual coding activities involved in a hack day (basically throwing code together until it worked), Kirsten designed and built the puppet from scratch.
This obviously required a fair bit of planning and organisation upfront. She had to have an idea of what the puppet would look like in order to select which materials she’d need to bring to the hack day. She had to bring in her sewing machine (the first sewing machine at a Music Hack Day!) and a big bag of fabric as well as the other tools required to make the puppet.

It was really interesting to see the process that she took. Based on a simple sketch for the design, she created a pattern: a paper template from which she made the preliminary shape for the puppet. After some tweaking, she adjusted the pattern and cut the fabric for the final puppet prototype. Then it was a matter of sewing it all together and finishing it off.
It really made me appreciate how lucky software and web developers have it: all we need is a laptop and internet connection and we’re effectively limited by our imagination and ability.
## Hacking with iOS
The Screecha app was actually the first time I developed a native iOS application. It was implemented using PhoneGap, so most of the user interface was developed using HTML/CSS/Javascript and Twitter Bootstrap. However, I did have to integrate cocoalibspotify so I did get to tinker about with some Objective C.
As a Hackday prototype, it was actually a bit disappointing to have developed a proof of concept that couldn’t be shared or made publicly accessible. If I had to do it again, I think I would go down the mobile webapp route using the HTML5 Audio API.
## Focus
From the start, we had a really clear idea of what we wanted to build: a puppet and a simple app that allowed you to play music, record sounds and upload them to SoundCloud.
We focused on implementing just that, resisting the temptation to add more features to the app or consider hacking some hardware into the puppet - there simply wouldn’t have been enough time to complete the prototype otherwise.
In my experience, good hacks can be the result of lots of iteration, last minute changes and a great deal of “hacking”. With Screecha, we took a good idea and focused on implementing just the essential features.
Screecha won an award from Spotify for best use of the Spotify API, and an award from SoundCloud.